1. 데이터의 정의
(1) 데이터의 정의
1. 데이터의 정의
- 데이터는 라인터 dare(주다), Datum(주어진 것)에서 왔으며 보통 연구나 조사 등의 바탕이 되는 재료 혹은 자료를 의미함
- 1646년 영국 문헌에서 처음 등장했으며 처음엔 추상적인 개념이었다가 1900년대 중반 컴퓨터의 시대가 도래하며 사실적인 의미의 '자료'로 의미가 변화함
2. 데이터의 특성
- 데이터에 있는 그대로의 사실 즉, 객관적인 사실을 의미함 (수학 80점, 영어 100점)
- 정보는 이러한 데이터로부터 얻은 것으로 '수학과 영어 점수의 평균은 90점'과 같이 가공된 자료를 의미
- 데이터의 존재적 특성: 있는 그대로의 사실을 나타내는 것
- 데이터의 당위적 특성: 추론/예측/전망/추정을 위한 정보의 근거가 될 수 있는 것
(2) 데이터의 유형
1. 정성적 데이터와 정량적 데이터
- 정성적 데이터: 언어와 문자 등 집합으로 표현할 수 없는 기준이 명확하지 않은 데이터
- 정량적 데이터: 수치, 도형, 기호 등 집합으로 표현할 수 있는 기준이 명확한 데이터
2. 정형 데이터와 비정형 데이터, 반정형 데이터
- 정형 데이터: 고정된 틀을 가지고 있으면서 계산이 가능한 데이터, 관계형 DB에 주로 저장
- 비정형 데이터: 고정된 틀이 존재하지 않고 연산이 불가능한 데이터, 관계형 DB가 아닌 NoSQL DB에 저장
- 반정형데이터: 고정된 형태는 있지만 연산이 불가능한 데이터, 테이블보다는 파일 형태로 저장하며 가공을 거쳐 정형데이터로 변환 가능
3. 암묵지와 형식지
- 암묵지: 학습과 체험을 통해 개인에게 습득되어 있지만, 겉으로 드러나지 않는 상태의 지식 (언어와 문자를 통해 나타나지 X)
- 형식지: 암묵지가 문서나 매뉴얼처럼 외부로 표출돼 여러 사람이 공유할 수 있는 지식 (교과서, 데이터베이스, 신문 등)
- 암묵지와 형식지의 상호작용: 공유화되기 어려운 암묵지가 형식지로 표출되고 연결되면 그 상호작용으로 지식이 형성됨, 개인에게 내면화된 암묵지가 조직의 지식으로 공통화되기 위해서는 표출화하고 이를 다시 개인의 지식으로 연결화/내면화 해야함
| 암묵지 | - 공통화, 내면화 |
| 형식지 | - 표출화, 연결화 |
2. 데이터와 정보
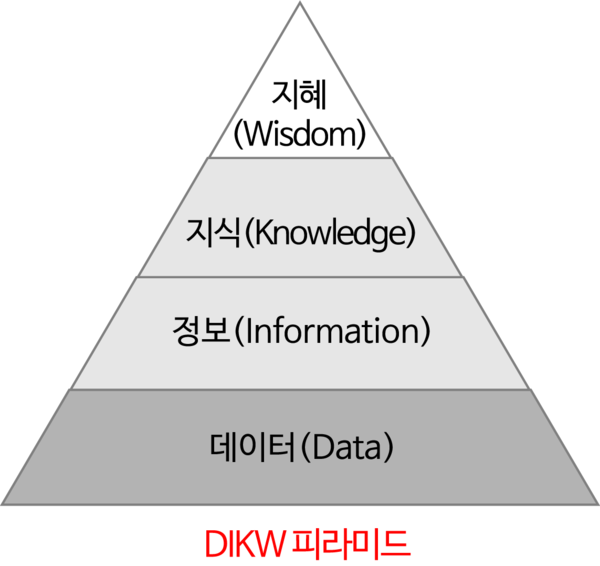
(1) DIKW 피라미드
1. 데이터에서 지혜를 얻는 과정
- 데이터: 객관적 사실
- 정보: 데이터로 인해 도출된 의미
- 지식: 데이터를 통해 도출된 정보를 분류하고 개인적 경험을 결합해 고유의 지식으로 내재화된 것
- 지혜: 지식의 축적과 아이디어가 결합된 창의적 산물
2. DIKW 피라미드
(2) 데이터에 관한 상식
1. 비트와 바이트
- 비트: 0과 1 두 가지 값으로 신호를 나타내는 최소단위
- 바이트: 8개의 비트로 구성된 데이터의 양을 나타나는 단위, 1바이트로는 숫자와 영어 한 글자 표현 가능 (한글은 두 글자)
2. 데이터 단위
- 1바이트 = 8비트
- 1킬로바이트 = 1024바이트
- 1메가바이트 = 1024킬로바이트
- 1기가바이트 = 1024메가바이트
- 1테라바이트 = 1024기가바이트
3. 데이터베이스 개요
(1) 데이터베이스 정의
1. 데이터베이스 용어의 연혁
- 1950년대: 미군에서 데이터와 기지의 합성어로 처음 등장
- 1963년: 미국 SDC가 개최한 심포지엄에서 '다량의 데이터를 축적하는 기지'라는 개념으로 공식적으로 처음 사용
- 1975년: 한국과학기술정보센터에서 사용한 것이 우리나라의 최초 사례
2. 데이터베이스의 정의
| DB | 체계적으로 수집/축적하여 다양한 용도와 방법으로 이용할 수 있게 정리한 정보의 집합체 |
| DBMS | 이용자가 쉽게 데이터베이스를 구축/유지할 수 있게 하는 관리 소프트웨어 |
(2) 데이터베이스의 특징
1. 데이터베이스의 일반적인 특징
- 통합된 데이터: 동일한 내용의 데이터가 중복되지 않아야함
- 저장된 데이터: 컴퓨터가 접근할 수 있는 저장 매체에 저장되어 있다
- 공용 데이터: 여러 사용자가 서로 다른 목적으로 데이터베이스의 데이터를 공동으로 이용할 수 있다
- 변화하는 데이터: 데이터의 삽입/수정/삭제의 변화를 통해 항상 최신의 데이터 상태를 유지한다
2. 데이터베이스의 다양한 측면에서의 특성
| 정보의 축적 및 전달 | - 기계 가독성 (컴퓨터 등 정보처리기기가 읽고 쓸 수 있음) - 검색 가능성 - 원격 조작성 |
| 정보이용 | - 이용자의 요구에 따라 다양한 정보를 신속/정확/경제적으로 찾을 수 있음 |
| 정보관리 | - 정보를 일정한 질서와 구조에 따라 정리/저장/검색/관리할 수 있게 하여 체계적으로 정보 축적 |
| 정보기술발전 | - 데이터베이스는 소프트웨어, 하드웨어, 네트워크 기술 등의 발전을 견인할 수 있음 |
| 경제/산업적 | - 데이터베이스는 다양한 정보를 신속하게 제공할 수 있는 특성을 가지고 있어 경제적 + 편의 증징 |
4. 데이터베이스 활용
(1) 데이터베이스 활용
1. 기업내부의 데이터베이스
- 인하우스 DB: 1990년대
- OLTP: 1990년대 중반 이전, 단순 자동화 중심의 시스템 (각각의 거래 단위 초점)
- OLAP: 데이터마이닝 기술이 등장하며 분석이 중심이 되는 시스템 구축 (전체 데이터에 초점)
- CRM과 SCM: 2000년대에 들어서며 고객관계관리와 공급망관리로 DB 구축의 화두가 변함
- KMS: 지식 경영 시스템
- ERP: 경영 자원 통합 관리
- BI: 비즈니스 인텔리전스로, 기업의 의사결정 프로세스 의미
- RTE: 업무 프로세스에서 발생하는 정보를 실시간으로 통합 및 전달해서 신속한 대응이 가능한 스피드 경영
2. 산업 부문별 데이터베이스 발전과정
| 제조 부문 | - 데이터베이스 기술의 가장 중요한 적용 분야 - 재고관리 -> 전 공정 관리로 확대 - 최근 인하우스 DB 구축이 주류 |
| 금융 부문 | - 1998년 IMF 이후 부실을 타파하기 위해 금융권 통합 시스템 구축이 확산 - 2000년대 초 데이터베이스 간 정보 공유 및 통합이나 고객 정보의 전략적 활용이 주 - 2000년대 중반 DW를 적극적으로 도입해 DB 마케팅 증대를 위한 노력 및 DW를 위한 최적 BI 기반 시스템 구축 |
| 유통 부문 | - 2000년대 이후 IT 변화 환경에 맞물려 CRM과 SCM 구축이 이루어짐 - 2000년대 중반 체계적인 고객정보 수집, 분석과 상권분석 등으로 심화 - 다양한 고객 분석 툴을 통해 기존 데이터베이스와 연계 - 전자태그(RFID)의 등장은 대량 유통 부문에 적용되었을 때 파급 효과가 매우 커, 대용량 DB 플랫폼이 요구됨 |
3.사회기반구조로서의 데이터베이스
- 1990년대 사회 각 부문의 정보화가 본격화되며 DB 구축이 활발하게 추진됨
| 물류 부문 | - 실시간 차량 추적을 위한 종합물류정보망 구축 - CALS: 제품의 설계/개발/생산에서 유통/폐기에 이르기까지 제품의 라이프사이클 전반의 데이터 통합 시스템 |
| 지리 부문 | - GIS(지리정보시스템) 응용에 활용하는 4S 통합기술 - 지리정보유통망 가시화 |
| 교통 부문 | - 지능형교통정보시스템, 교통정보, 대국민 서비스 확대 |
| 의료 부문 | - 의료정보시스템 - 전국적인 진료 정보 공유 체계 구축 계획 수립 - U헬스 실현에 기존 의료정보 데이터베이스 기반 활용 |
| 교육 부문 | - 첨단 정보통신기술을 활용한 각종 교육 정보의 개발 및 보급, 정보 활용 교육 - 대학 정보화 및 교육행정 정보화 위주로 사업 추진 - 교육행정정보시스템(NEIS)은 학사 |
(2) 데이터베이스 종류
1. 데이터베이스의 종류
- 관계형 데이터베이스: 데이터를 행과 열로 이루어진 테이블에 저장하며, 하나의 열은 하나의 속성을 나타내고 같은 속성의 값만 가질 수 있다. 데이터 저장 방식이 엑셀과 유사하며 정형 데이터를 다루는 데 특화되어 있다. (ex. MySQL)
- NoSQL: Not only SQL, Non SQL, Non-relational의 의미로 비관계형 DB라는 의미이다. 비정형 데이터와 대용량의 데이터 분석 및 분산처리에 용이
- 계층형 DBMS: 데이터가 부모-자식 관계를 갖도록 관리하지만, 중복 문제가 발생하기 쉬움
- 네트워크형 DBMS: 네트워크 형태로 관리하지만 복잡한 구조로 인해 구조 변경이 어려움
- 분산형 DBMS: 분산된 여러 개의 데이터베이스를 하나의 데이터베이스로 인식하고 사용할 수 있음
- 객체지향 DBMS: 사용자가 정의하는 타입을 하나의 데이터 유형으로 저장
2. SQL의 이해
- 데이터베이스에 명령을 내리는 데이터베이스의 하부 언어
- 한국데이터산업진흥원은 기본적으로 Oracle을 기반으로 함
| DDL | 데이터 정의 언어 | - CREATE: 테이블 생성 - ALTER: 테이블 정보 변경 - RENAME: 테이블 이름 변경 - DROP: 테이블 삭제 |
| DML | 데이터 조작 언어 | - SELECT: 테이블 데이터 조회 - INSERT: 테이블에 데이터 삽입 - UPDATE: 테이블에 포함된 데이터 변경 - DELETE: 테이블에 포함된 데이터 삭제 |
| DCL | 데이터 제어 언어 | - GRANT: 사용자에게 권한 부여 - REVOKE: 사용자로부터 권한 회수 |
| TCL | 트랜잭션 제어 언어 | - COMMIT: 변경된 데이터 적용 - SAVEPOINT: 현재 데이터 상태 기억 - ROLLBACK: COMMIT이 되지 않았다면 변경사항들에 대한 명령 철회 or 세이브포인트 지점으로 돌아가기 |
- 인스턴스: 하나의 객체 (행)
- 속성: 객체를 표현하기 위해 사용되는 값 (열)
- 엔터티: 데이터의 집합 (테이블) (2개 이상의 인스턴스와 1개 이상의 속성을 보유해야함)
'ADsP' 카테고리의 다른 글
| [ADsP] 3. 데이터 분석 기획의 이해(2) (0) | 2026.01.31 |
|---|---|
| [ADsP] 3. 데이터 분석 기획의 이해(1) (1) | 2026.01.30 |
| [ADsP] 2. 데이터의 가치와 미래 (2) (1) | 2026.01.30 |
| [ADsP] 2. 데이터의 가치와 미래 (1) (1) | 2026.01.29 |