1. 로지스틱 회귀분석 개요
(1) 로지스틱 회귀분석
- 종속변수가 범주형일 경우에 사용하는 분류 분석
(2) 로지스틱 회귀분석의 변수
- 종속변수가 이진이어야 하며, 세 개 이상의 집단을 분류할 땐 다중 로지스틱 회귀분석이라 함
- 독립변수가 연속형이면서 종속변수가 범주형일 때 사용 가능
- 종속변수는 확률값으로 반환됨
2. 로지스틱 회귀분석의 알고리즘
(1) 오즈
- 성공할 확률이 실패할 확률의 몇 배인지를 나타내는 값
(2) 로짓변환
- 오즈는 양수값이며, 그래프는 비대칭성을 띠기에 이러한 한계를 극복하기 위해 오즈에 로그값을 취하는 것 (= 로짓)
- 범위가 무한대로 확장되며, 로짓값의 그래프는 성공확률 0.5를 기준으로 대칭 형태를 띰
(3) 시그모이드 함수
- 로지스틱 회귀분석과 인공신경망 분석에서 활성화 함수로 자주 사용
- 로짓 함수와 역함수 관계이기 때문에 로짓함수를 통해 시그모이드 함수 도출
4. 의사결정나무의 분석 과정
(1) 성장
a. 성장단계
- 분석 목적과 자료구조에 따라 적절한 분리 기준 및 정지 규칙을 설정해 의사결정나무를 성장시키는 단계
- 각 마디에서 최적의 분리 규칙을 찾아 의사결정나무를 형성하고 적절한 정지 규칙을 만족하면 나무의 성장을 중단
b. 분리기준: 불순도를 기준으로 함. 불순도가 가장 크게 감소할수록 최적의 분할이 됨
c. 정지규칙: 의사결정나무가 너무 많은 분리 기준을 보유하면 해석의 어려움이 발생, 특정 조건에서 더 이상 분리가 되지 않게 조정
d. 분리기준
- 종속변수가 이산형일 때: 카이제곱통계량, 지니지수, 엔트로피지수를 분리기준으로 사용
- 종속변수가 연속형일 때: ANOVA F-통계량, 분산감소량을 분리기준으로 사용
e. 지니지수 계산
- 앞면의 확률이 3/4이고 뒷면의 확률이 1/4일때, 1-(3/4)^2 - (1/4)^2 = 6/16
(2) 가지치기
- 의사결정나무도 과적합/과소적합이 발생할 수 있어 일부 가지를 적당히 제거해줌
(3) 타당성 평가
- 예측 정확도를 평가하거나 이익 도표 등의 평가 지표를 통해 의사결정나무를 평가
(4) 해석 및 예측
6. 앙상블 분석 개요
- 여러 개의 모형을 생성 및 조합하여 예측력이 높은 모형을 만듦
- 회귀분석과 분류분석 모두에 사용 가능
- 결과가 수치형일 땐 평균으로 결과를 예측, 범주형일 땐 다수결 방식으로 결과를 예측
7. 앙상블 분석의 종류
(1) 배깅
- Bootstrap Aggregating의 줄임말로, 여러 개의 부트스트랩을 집계하는 알고리즘
- 여러 개의 분류기에 의한 결과를 놓고 다수결에 의해 최종 결과값을 선정하는 작업을 '보팅'이라 함
- 모집단의 분포를 알 순 없지만, 모집단의 특성이 잘 반영되는 분산이 작고 좋은 예측력을 보임
(2) 부스팅
- 여러 개의 모형을 구축하지만, 각 분류기가 독립적이지 않음
- 이전 모델을 구축한 뒤, 다음 모델을 구축할 때 이전 분류기에 의해 잘못 분류된 데이터에 더 큰 가중치를 주어 부트스트랩을 구성함
- 약한 모델을 결합하여 나감으로써 점차 더 강한 분류기를 만들어나감
(3) 랜덤포레스트
- 서로 상관성이 없는 나무들로 이루어진 숲 (배깅과 유사하나, 배깅에 더 많은 무작위성을 줌)
- 여러 개의 약한 트리들의 선형 결합으로 최종 결과를 얻음
- 각 마디에서 최적의 분할을 하는 것이 아닌, 표본추출 과정을 거쳐 새로운 표본을 대상으로 최적의 분할을 진행시킴
- 큰 분산을 갖고있다는 의사결정나무의 단점을 보완, 이상값에 민감하지 않음
8. 인공신경망 개요
- 인간의 뇌를 모방하여 만들어진 학습 및 추론 모형
- 값이 입력되면 개별 신호의 정도에 따라 값이 가중되며, 가중도니 값에 편향이라는 상수를 더한 후 활성함수를 거침
- 장점: 잡음에 민감하지 않음, 비선형 문제 분석 유용, 패턴인식/분류/예측에 효과적
- 단점: 긴 학습 시간, 가중치의 신뢰도 문제, 해석의 어려움, 은닉층의 수와 은닉 노드의 수 결정의 어려움
9. 인공신경망의 알고리즘
(1) 활성함수
- 인공신경망은 노드에 입력되는 값을 바로 다음 노드로 전달하지 않고, 비선형 함수(활성함수)에 통과시킨 후 전달함
| Step | - 기본적인 활성함수로 0 또는 1을 반환하는 이진형 함수 |
| Sigmoid | - 로지스틱 회귀분석의 확률값을 구하기 위한 식과 유사하며, 0과 1 사이의 값을 반환 |
| Sign | -1 또는 1을 반환하는 이진형 함수 |
| tanh | - 확장된 형태의 시그모이드 함수로, 중심은 0이며 -1과 1사이의 값을 출력 |
| ReLU | - 입력값과 0 중에서 큰 값을 반환 |
| Softmax | - 출력값이 다범주인 경우에 사용하며, 각 범주에 속할 확률값을 반환함 (로지스틱과 유사) |
(2) 인공신경망의 계층 구조
- 입력층, 은닉층, 출력층으로 구성
- 은닉층은 다층신경망의 경우에만 사용하며, 입력층과 츨력층 사이에 보이지 않는 다수의 은닉층이 존재
- 입력층은 데이터를 입력받아 시스템으로 전송하며, 은닉층은 입력층으로부터 값을 전달받아 가중치를 계산한 후 활성함수에 적용하여 결과를 산출해 출력층으로 보냄
- 출력층은 활성함수의 결과를 담고 있는 노드로 구성되며 노드의 수는 출력 범주의 수로 결정됨 (분류 문제에선 노드에 확률이 포함)
(3) 인공신경망 학습(역전파 알고리즘)
- 인공신경망은 여러 개의 퍼셉트론으로 구성되어있기 때문에 각 퍼셉트론이 보유한 여러 개의 가중치 값의 결정이 중요
- 입력층과 출력층의 데이터에 따른 이상적인 가중치 wi 값을 결정해야함
- 순전파 알고리즘: 입력층 -> 출력층으로 찾아나감
- 역전파 알고리즘: 출력층에서 입력층 방향으로 거꾸로 찾아나가며 가중치 값을 새롭게 조정
- 학습이 한번 되는 것을 1 epoch라고 하면, 일정 수의 epoch에 도달하거나 원하는 수준의 정확도를 얻을 때까지 반복
10. 인공신경망의 종류
(1) 단층 퍼셉트론(단층 신경망)
- 입력층이 은닉층을 거치지 않고 바로 출력층과 연결
- 여러 개의 개별 입력 데이터를 받아 하나의 입력 데이터로 가공해 활성함수에 의해 출력값을 결정
- 이러한 퍼셉트론의 출력값은 또 다른 퍼셉트론의 입력 데이터가 됨
- 출력값이 정해진 임곗값을 넘었을 경우 1을 출력하고, 넘지 못했을 경우에는 0을 출력
(2) 다층 퍼셉트론(다층 신경망)
- 다수의 은닉층을 가지고 있을 수 있음
- 너무 적은 은닉층과 은닉노드는 과소적합 문제가 발생하기에 적절한 노드의 수를 찾는 것이 중요
11. 베이즈 이론(베이지안 확률)
- 빈도확률: 사건이 발생한 횟수의 장기적인 비율, 근본적으로 반복되는 어떤 사건의 빈도
- 베이지안 확률: 사전확률과 우도확률을 통해 사후확률을 추정 (사전지식까지 포함)
12. 나이브 베이즈 분류
(1) 개념
- 베이즈 정리를 기반으로 한 지도학습 모델로, 스펨 메일 필터링, 텍스트 분류 등에 사용 가능
- 데이터의 모든 특징 변수가 동등하고 독립적이라는 가정하에 분류를 실행 (질환 유무를 분류할 수 있게 해주는 특성은 서로 연관 X)
(2) 알고리즘
- 이진 분류 데이터가 주어졌을 때 베이즈 이론을 통해 범주 a,b가 될 확률을 구하고, 더 큰 확률값이 나오는 범주에 데이터를 할당하는 알고리즘
13. K-NN 알고리즘
(1) 개요
- k-NN 혹은 k-최근접이웃으로 불리는 분류 알고리즘 (지도학습이지만, 군집의 특성도 가지고 있어 준지도학습으로도 불림)
- 정답 라벨이 있는 데이터들 속에서 정답 라벨이 없는 데이터들을 어떻게 분류할 것인지에 대한 해결방법으로 사용
(2) 원리
- 정답 라벨이 없는 새로운 데이터를 받았을 때 그 데이터로부터 가장 가까이에 있는 데이터의 정답 라벨을 확인하여 새로운 데이터의 정답 라벨을 결정
- k값에 따라 새로운 데이터가 어떤 정답으로 분류될지가 달라져, k값의 결정이 중요함
14. 서포트벡터머신
(1) 개요
- 지도학습에 주로 이용되며, 분류 분석에 사용
- 초평면을 이용하여 카테고리를 나누어 비확률적 이진 선형모델을 만듦
(2) 알고리즘
- 분류할 때 가장 높은 마진을 가져가는 방향으로 분류함
- 마진이 크면 클수록 학습에 사용하지 않는 새로운 데이터가 들어오더라도 분류를 잘 할 가능성이 높음
- 일반적으로 서포트벡터머신은 분류 또는 회귀분석에 사용 가능한 초평면 또는 초평면들의 집합으로 구성됨, 초평면이 가장 가까운 데이터와 큰 차이를 가진다면 오차가 작아지기 때문에 좋은 분류를 위해선 어떤 분류된 점에 대해 가장 가까운 학습 데이터와 가장 먼 거리를 가지는 초평면을 찾아야함
15. 분류 모형 성과평가
(1) 오분류표와 평가지표
- 분류 분석 후 예측한 값과 실제 값의 차이를 교차표 형태로 정리한 것을 오분류표 혹은 confusion matrix라고 부름
- 평가용(test) 데이터로부터 계산되어 얻은 표
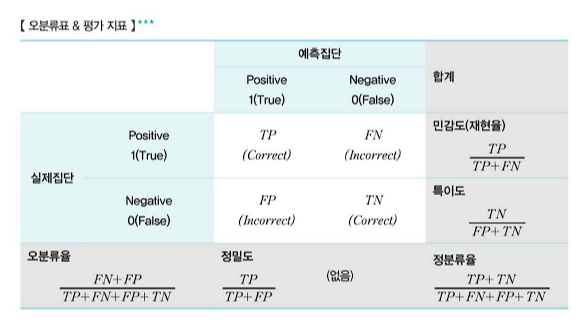
- 민감도(재현율, Recall): 실제 True 중 True로 예측한 비율
- 특이도(Specificity): 실제 False 중 False로 예측한 비율
- 정밀도(Precision): 예측 True 중 실제 True인 비율
- F1 Score: 정밀도와 재현율의 조화평균 (2 * Precision * Recall / Precision + Recall)
(2) ROC 커브
- x축은 FPR (1-특이도), y축은 TPR (민감도) 값을 갖는 그래프
- ROC 커브 아래의 면적을 나타내는 AUROC의 값이 1에 가까울수록 모형의 성능이 우수, 0.5에 가까울수록 랜덤 모델
(3) 이익도표
- 목표범주에 속할 확률을 내림차순으로 정렬하여 몇 개의 구간으로 나누어 각 구간에서의 성능을 판단하고 랜덤모델보다 얼마나 더 뛰어난 성능을 보이는지를 판단하는 표
- 일반적으로 0.5에서 cut-off 하며, 1.0이 가장 높은 기준이 됨
- 반응률: 해당 구간에서의 범주 빈도수 / 전체 데이터 개수
- 향상도: 반응률/랜덤모델의 예측력
(4) 향상도 곡선
- 좋은 모델일수록 큰 값에서 시작하여 급격히 향상도가 감소함
'ADsP' 카테고리의 다른 글
| [ADsP] 15. 연관분석 (0) | 2026.02.05 |
|---|---|
| [ADsP] 14. 군집분석 (0) | 2026.02.05 |
| [ADsP] 12. 데이터마이닝 (0) | 2026.02.04 |
| [ADsP] 11. 시계열 분석 (0) | 2026.02.03 |