1. 변수간의 관계
회귀분석(regression analysis)은 하나의 변수와 다른 여러 변수간의 관계를 밝히기 위한 통계적 기법이다. 회귀분석은 대표적으로 두가지로 나뉜다.
● 단순회귀분석(simple regression analysis) : 하나의 변수와 다른 또 하나 변수간의 관계를 분석하는 방법
● 다중회귀분석(multiple regression analysis) : 하나의 변수와 둘 또는 그 이상 변수간의 관계를 분석하는 방법
우선 단순회귀분석을 먼저 봤을 때, 다음은 2007년 국민건강영양조사 중에서 만 10세 - 90세의 한국인 남성 4,514명을 대상으로 키와 몸무게의 자료를 요약한 것이다.
| 평균키 = 167.5cm | 키의 표준편차 = 8.5cm |
| 평균몸무게 = 63.5kg | 몸무게의 표준편차 = 11.9kg |
| 상관계수 = 0.67 |
일반적으로 키가 큰 사람은 몸무게도 많이 나갈 것이다. 구체적으로 키가 1단위 증가하면 몸무게는 평균적으로 몇 단위나 증가할까?

그림의 가로축은 키를, 세로축은 몸무게를 나타내며 축의 간격은 각각의 표준편차로 정해져있다. 키와 몸무게의 표준단위가 같은 점들은 평균점을 지나는 점선으로 그려져 있으며, 이를 표준편차선(SD line)이라고 한다. 표준편차선은 키와 몸무게의 표준화된 변수 값이 같은 점들을 이은 직선이다.
평균키보다 키의 표준편차 단위로 1SD만큼 큰 곳에 점선으로 세로띠가 그려져있다. 세로띠 안의 점들 가운데 표준편차선상의 점은 몸무게가 평균몸무게보다 몸무게의 표준편차 단위로 1SD만큼 더 나가는 사람을 나타낸다. 해당 세로띠 내에선 표준편차선보다 아래에 위치한 점들이 더 많은데, 키가 1SDx만큼 크다고 해서 몸무게도 1SDy만큼 무겁지는 않은 게 일반적이란 것이다.
※ SDx는 x의 표준편차, SDy는 y의 표준편차를 의미함
위의 자료들을 종합한 결과, 다음과 같은 결과가 나온다.
① 평균키보다 키가 표준편차 단위로 한 단위 큰 사람의 키는 176cm이다. (167.5cm + 8.5cm = 176cm)
② 위의 사람들의 평균몸무게는 전반적인 평균몸무게보다 0.67SDy만큼 더 나가는 경향이 있다. (0.67 * 11.9kg ≈ 8.0kg) ※상관계수가 0.67이기에 x가 1SDx만큼 증가하면 y는 0.67SDy만큼 증가한다.
③ 따라서 세로띠 안에 있는 사람들의 평균몸무게는 대략 63.5kg + 8.0kg = 71.5kg이 될 것이다.
그림의 X들은 각각 평균키로부터 -2SD, 0, +1SD, +2SD만큼 큰 사람들의 평균 몸무게를 나타낸 점이다. 이런식으로 이은 점들을 모두 이으면 하나의 선이 얻어지며, 이 직선을 몸무게의 키에 대한 회귀직선(regression line)이라 한다.
회귀직선상에서 키가 1SDx 증가할 때, 몸무게는 0.67SDy만큼만 증가한다. 키를 기준으로 사람들을 여러 집단으로 구분한다고 했을 때, 평균키를 가진 집단, 평균키보다 1SDx 더 큰 집단 등 어느 한 집단에서 다음 집단으로 넘어갈 때, 키는 1SDx씩 증가하나 몸무게는 0.67SDy씩만 증가한다. 이처럼 각각의 x값에 대응하는 y값의 평균치를 추정하는 방법을 회귀분석이라 부른다.
일반적으로 y의 x에 대한 회귀직선은 각각의 x값에 대응하는 y의 평균값을 추정한다.
※ 표준편차선은 각 변수들의 표준단위가 같은 점들을 이은 것이며 (상관관계 고려 x)
ex. 평균으로부터 ± n 표준편차
※ 회귀직선은 x 변수에 대한 y 평균을 나타낸 점들을 이은 것이다. (상관관계 고려 o)

다음과 같이 x가 평균값에서 1SDx만큼 증가하면 y는 평균적으로 r * SDy만큼만 증가한다.(r은 상관계수) SDx는 x가 퍼진정도를, SDy는 y가 퍼진 정도를 측정한다.
2. 평균의 그래프
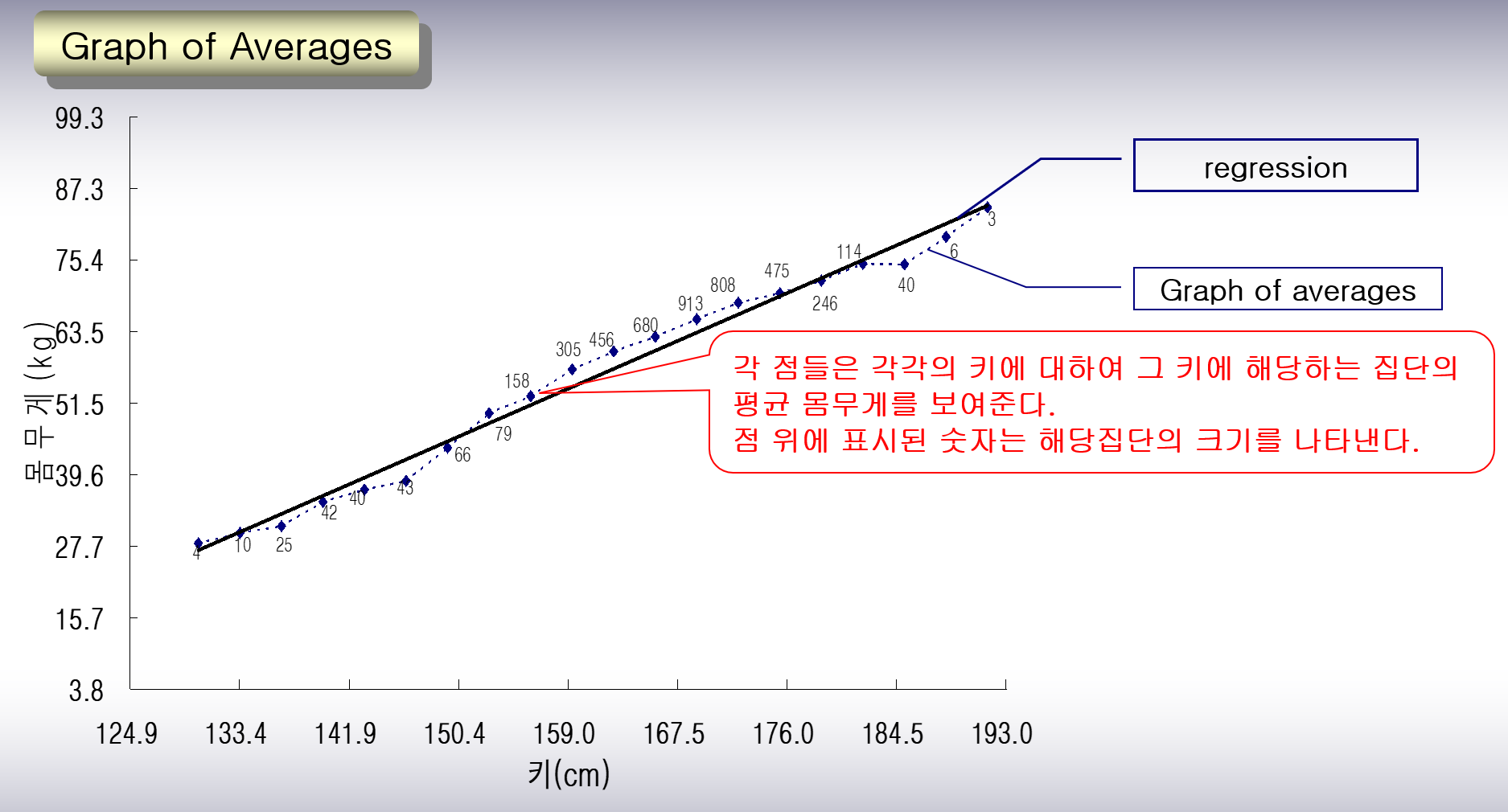
점 위에 표시된 숫자는 해당집단의 크기(수)를 나타낸다. 점의 y축 좌표는 키에 따라 분류된 집단별 평균 몸무게를 나타낸다. 평균으로 이루어진 점들을 이으면 평균의 그래프를 얻을 수 있다. 점선으로 표시된 평균의 그래프는 하나의 직선에 의해 근사가 잘 될 것처럼 보이며, 회귀직선이란 바로 평균의 그래프를 하나의 직선으로 근사시킨 것에 해당한다.

다만, 다음과 같이 두 변수가 비선형관계에 있다면 회귀직선은 비선형 관계를 제대로 반영하지 못한다. 이때는 평균의 그래프를 근사시키지 말고 있는 그대로, 즉 비선형의 형태로 쓰는 편이 더 낫다.
회귀직선 : 평균의 그래프를 하나의 직선으로 근사시킨 것. 평균의 그래프 자체가 직선이라면 그 직선이 바로 회귀직선
3. 회귀분석방법
(1) 표준편차를 이용한 회귀 분석
앞서 이용한 키와 몸무게의 자료를 다시 요약해보자.
| 평균키 = 167.5cm | 키의 표준편차 = 8.5cm |
| 평균몸무게 = 63.5kg | 몸무게의 표준편차 = 11.9kg |
| 상관계수 = 0.67 |
임의로 한 사람을 선택했을 때, 그 사람에 대한 추가적인 정보가 없으면, 그의 몸무게는 전반적인 평균과 같은 63.5kg이라고 추정한다. 다음으로 그의 키가 179.5cm라는 정보를 얻게 되면, 그의 몸무게는 키가 179.5cm인 사람들의 평균 몸무게 정도일 것으로 추정한다.
예시문제) 다음은 한 대학의 경제학과 학생 100명을 대상으로 경제원론의 학점과 경제통계학의 학점을 조사하여 다음 통계치를 얻은 자료이다.
| 경제원론 평균학점 = 3.00 | 표준편차(SDx) = 0.70 |
| 경제통계학 평균학점 = 3.00 | 표준편차(SDy) = 0.60 |
| 상관계수 = 0.5 |
산포도는 타원형이며, 경제원론의 학점이 A-로 3.70인 지수의 경제통계학 학점을 추정해보자.
● 지수의 학점은 평균보다 0.7이 높으며 이는 1SDx와 같다.
● 회귀분석방법을 이용해 경제통계학 학점을 구하면, 지수의 경제통계학 학점은 0.5 * 1SDy = 0.5SDy만큼 높다.
(경제원론의 점수가 평균보다 1SDx만큼 높으니, 경제통계학의 점수는 평균보다 상관계수 * 1SDy만큼 높은 것이다.)
● 따라서 지수의 경제통계학 학점은 3.00 + (0.5 * 0.60) = 3.30으로 추정할 수 있다.
이처럼 새로운 개체의 값을 추정할 때 기존의 자료로부터 구한 회귀직선이 종종 이용된다. 담나 이 방법은 기존의 자료가 새로운 개체를 대표할 수 있는 경우에만 타당하다. 새로운 개체가 기존의 자료와 성격이 다르거나 자료의 범위가 다르면 회귀분석의 적용에 앞서 주의를 기울여야 한다. 다음의 예시를 보자.
① 지수가 경제학과 학생이 아니고 철학과 학생이라고 해보자.
경제학과생의 자료로부터 추정한 경제원론 점수와 경제통계학 점수간의 관계가 철학과 학생인 지수에게도 그대로 적용될 것인지에 대해 생각해봐야할 것이다.
② 지수의 경제원론 학점이 3.70이 아니고 4.30이라고 해보자.
기존 자료에서 경제원론 학점은 대부분 2.0 ~ 4.0 사이에 있다. 지수의 학점인 4.3은 기존 자료의 x값 범위 밖이다. x값을 기준으로 2.0 - 4.0 범위에서 추정된 회귀직선이 그 범위를 뛰어넘는 새로운 x값에 대해서도 그대로 적용될 것인지에 대한 생각이 필요하다. 이처럼 기존 자료의 범위를 뛰어넘는 x값에 대하여 그에 해당되는 y값을 예측하는 문제를 외삽(extrapolation)이라고 한다. 일반적으로 외삽은 잘못될 가능성이 더 크다.
(2) 백분위를 이용한 회귀분석
회귀분석 기법은 백분위를 예측하는 데에도 이용된다. 어떤 학생의 경제원론 학점이 백분위로 90%에 해당한다면, 나머지 90%가 그보다 못했다는 것을 의미한다.
예시문제) 위의 표를 그대로 사용했을 때, 건희는 경제원론 학점의 백분위가 90%라고 한다. 이로부터 그의 경제통계학 학점의 백분위를 예측해보자.
| 경제원론 평균학점 = 3.00 | 표준편차(SDx) = 0.70 |
| 경제통계학 평균학점 = 3.00 | 표준편차(SDy) = 0.60 |
| 상관계수 = 0.5 |

건희의 경제원론 학점은 평균보다 높다. 몇 SDx만큼 높을까. 경제원론 학점의 분포가 정규분포를 따르는 경우, 백분위로부터 표준화된 변수 정보를 알 수 있다. 표준화를 한 x값은 평균보다 몇 SDx만큼 떨어져있는지 나타낸다. 즉, z = 1.3일때 해당 값은 백분위 90%가 되며, 이는 평균보다 1.3SDx만큼 높은 값이라는 것이다.
건희의 경제원론(x) 학점은 1.3SDx만큼 높기 때문에, 경제통계학(y) 학점은 0.5(상관계수) * 1.3SDy = 0.65만큼 높을 것으로 예측된다.

이를 백분위로 환원시키면 다음과 같이 74%로 추정된다. 이는 상위 26%의 성적이며, 경제원론 상위 10%의 학생은 평균적으로 경제통계학에서 상위 26%의 성적을 받는다고 추측할 수 있다. 만약 두 학점간의 상관계수가 0이라면, 경제원론 학점의 백분위로 경제통계학 학점의 백분위를 예측할 수 없다.
4. 회귀효과
(1) 평범으로의 회귀
초등학교 5학년생 아이들에게 한 달 간격을 두고 두 번 IQ 검사를 실시하였다. 일차검사와 이차검사 모두 평균이 100점, 표준편차가 15점이었다. 그런데 일차검사에서 IQ가 평균보다 낮았던 아이들의 경우 이차검사에서 IQ가 평균적으로 5점 증가하였고, 그 반대 경우엔 이차검사에서 IQ가 평균적으로 5점 감소하였다.
일반적으로 첫 번째 검사에서 점수가 낮은 집단은 두 번째 검사에서 평균적으로 점수가 향상되고, 첫 번째 검사에서 점수가 높은 집단은 두 번쨰 검사에서 평균적으로 점수가 떨어지는 경향이 있다. 이를 회귀효과(regression effect)라 한다. 점들이 하나의 직선상에 위치하지 않고 퍼져있으면 항상 이러한 회귀효과가 발생하기 마련이다.
| 중간고사 성적의 평균 = 129.3 | 표준편차(SDx) = 30.8 |
| 기말고사 성적의 평균 = 112.4 | 표준편차(SDy) = 40.0 |
| 상관계수 = 0.64 |
위와 같은 자료가 주어져있을 때, 산포도는 아래와 같이 나타난다.
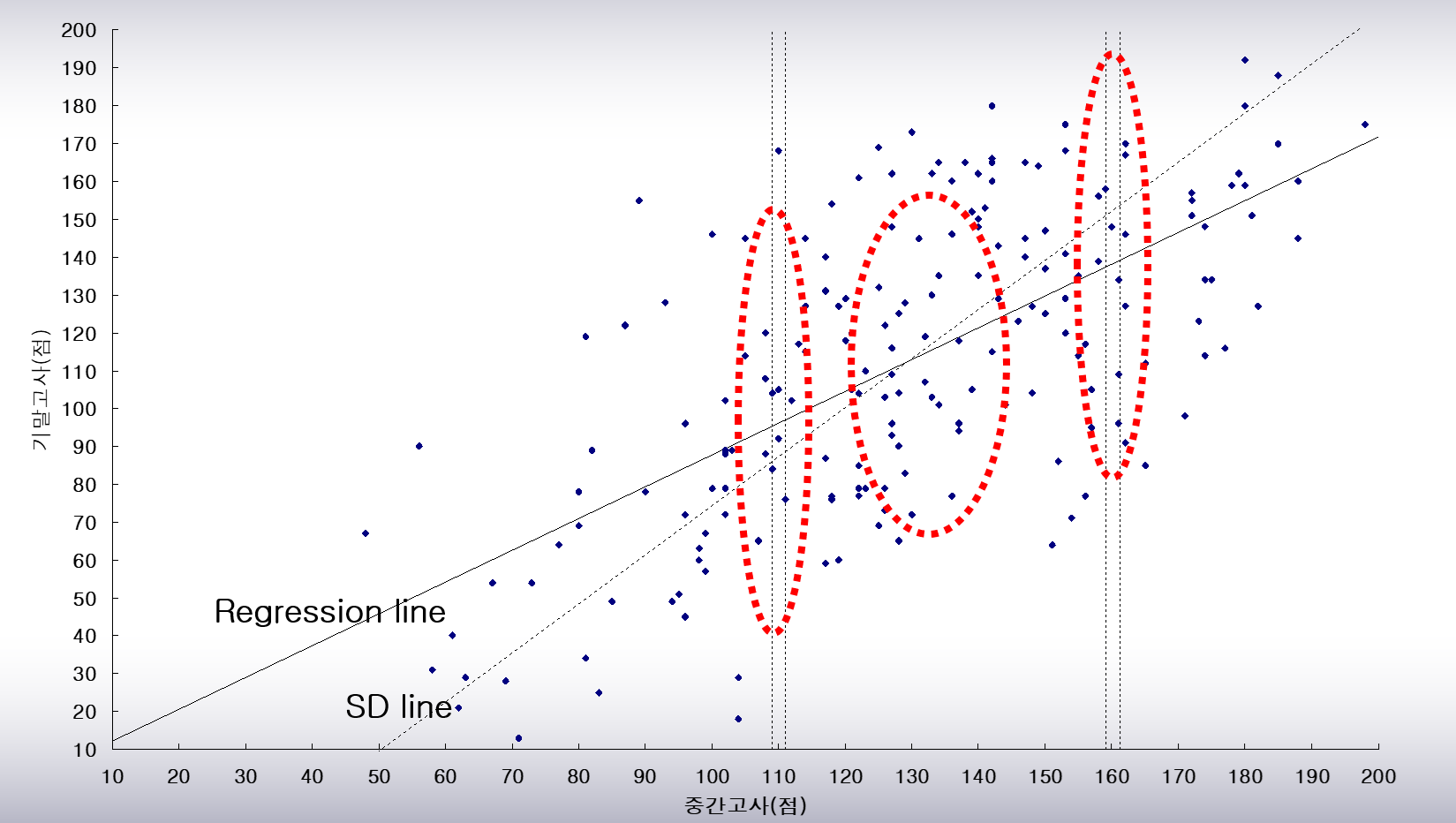
점선은 중간고사와 기말고사의 평균점수를 지나며 x가 1SDx만큼 증가할 때 y가 1SDy만큼 증가하는 표준편차선이다. 먼저 맨 우측의 중간고사 성적이 반올림하여 160점인 점들을 살펴보자. 이 점들은 오른쪽의 세로띠 안에 있으며, 표준편차선 기준으로 아래쪽에 더 많이 분포되어 있다. 중간고사 점수가 높은 수강생들의 기말고사 점수는 중간고사 점수에 비해 평균적으로 하락한다.
이번엔 중간고사 점수가 반올림하여 110점인 왼쪽 세로띠 안의 점들을 살펴보자. 이 세로띠 안의 점들은 표준편차선 기준으로 위쪽에 더 많이 분포되어 있다. 즉, 중간고사 점수가 낮은 수강생들의 기말고사 성적은 중간고사에 점수에 비해 평균적으로 상승한다.
중간고사를 평균보다 잘 본 학생은 기말고사에서 상대적으로 성적이 떨어지는 경향이 있고, 그 반대의 경우에는 성적이 향상되는 경향이 있다.
이러한 현상을 처음 발견한 갈튼(Francis Galton 영국, 1822-1911)은 이것에 대해 평범으로의 회귀(regression to mediocrity)라고 불렀다. 요즘엔 평균으로의 회귀로 더 잘 알려져 있는듯 하다.
점들은 표준편차선을 중심으로 대칭적으로 퍼져있다. 반면, 회귀직선은 각 세로띠의 중심점들에 가깝게 위치한다.
(2) 회귀효과 설명

위 그림은 회귀효과를 분명하게 보여준다. 개개의 점들은 각각의 중간고사 점수에 대응하는 기말고사 평균 점수를 나타낸다. 이 점들은 위 산포도에서 봤던 각 세로띠의 중심들이다. 이러한 점들을 하나의 직선으로 근사시키면 이는 회귀직선이 되는데, 표준편차선보다 완만하다.
이는 회귀효과 때문으로, 각각의 평균으로 이루어진 점들을 근사시킨 회귀직선은 표준편차선과 전반적인 평균을 지나는 수평선의 중간 어딘가에 위치한다. 왜냐면 상관계수가 0.64로서 1보다 작고 0보다 크기 때문이다. 점수가 1SDx 증가함에 따라 기말고사 점수는 1SDy(상관계수가 1일 때) 또는 0SDy(상관계수가 0일 때)가 아닌 0.64SDy만큼 증가한다.
회귀효과는 개개의 자료를 나타내는 점들이 하나의 직선상에 위치하지 않고 퍼져있기 때문에 발생한다. 그럼에도 사람들은 종종 회귀효과가 뭔가 다른 이유 때문에 발생한다고 오해한다. 이러한 오해를 회귀오류(regression fallacy)라고 부른다. 다음 모형을 예로 들어 회귀효과의 배경을 살펴보자.
| (관찰된 점수) = (실제 실력) + (확률오차) |
해당 모형에 따르면 실제 실력에 변화가 없는 한 첫 번째 검사와 두 번째 검사의 점수가 다른 것은 확률오차 때문이다. 첫 번째 검사에서 점수가 높게 나왔다면 운이 좋았을 가능성이 크다. 이는 두 번째 검사에서는 점수가 떨어질 가능성이 있음을 시사한다.
어느 모집단에서 실제 실력이 평균 120, 표준편차 15의 정규분포를 따른다고 가정하자. 확률오차는 각각 0.5의 확률로 ±5라고 하자. 따라서 실제 실력이 135인 사람의 관찰된 점수는 각각 1/2의 확률로 130 또는 140이 될 것이다.
첫 번째 시험에서 140을 얻은 사람들은 다음의 두 부류로 나눌 수 있다.
● 실제 실력은 135인데 확률오차가 +5인 경우
● 실제 실력은 145인데 확률오차가 -5인 경우

다음 그림에서 볼 수 있듯이, 실제 실력이 145인 사람보다는 135인 사람이 더 많다. 즉, 실제 실력은 135인데 확률오차가 +5인 경우가 더 일반적이다. 관찰된 점수가 140으로 평균점수 이상이기에, 실제 실력이 관찰된 점수보다 높을 가능성에 비해 낮을 가능성이 더 크다.
첫 번째 시험점수가 평균보다 높으면, 실제 실력은 관찰된 점수보다 낮을 가능성이 더 크다. 따라서 이 사람이 다시 시험을 치르면 두 번째 시험 점수는 처음보다 떨어질 가능성이 크다. 이것이 회귀효과의 원리이다.
* 해당 글은 류근관 저서의 <통계학> 제 3판의 내용을 바탕으로 합니다 *
'통계학' 카테고리의 다른 글
| [통계학] 데이터 사이언스 인터뷰를 위해 필수적으로 알아둬야 할 통계적 개념 (8) | 2024.12.11 |
|---|---|
| [통계학] 7장 - 회귀분석의 오차 (2) | 2024.12.07 |
| [통계학] 5장 - 상관관계 (5) | 2024.11.28 |
| [통계학] 4장 - 정규분포로의 근사 (2) | 2024.11.24 |



