1. 자료의 중심과 퍼진 정도
히스토그램은 많은 양의 자료를 그림으로 나타내며, 그에 따라 중심과 '중심 주위로 퍼진 정도'를 측정할 수 있다.
이때 평균(mean)과 중앙값(median)은 중심을 찾는 데 사용하며, 표준편차(standard deviation)와 사분위수 범위(interquartile range)는 중심으로부터 퍼진 정도를 측정하는 데 사용한다.

두 히스토그램은 동일한 중심을 갖고 있지만, 중심 주위로 퍼진 정도는 우측의 히스토그램이 더 크다.

해저의 지표가 해상의 지표보다 훨씬 많은 비중을 차지하고 있는 것을 알 수 있다. 또한, 봉우리가 두 개라는 사실은 중심의 의미를 퇴색시키고, 중심 주위로 퍼진 정도의 의미도 반감시킨다.
2. 평균, 중앙값, 최빈치
자료를 요약해주는 대표값으로는 평균(mean)과 중앙값(median), 그리고 최빈치(mode)가 있다.
(1) 평균(mean)

표본 평균은 x̄로 나타내며, n개의 관측치가 주어졌을 때 관측치의 총합을 관측치의 개수(n)로 나눈 것이다.

평균은 중요한 정보이지만, 전부는 아니다. 평균으로 자료를 요약하는 과정에서 개인적 차이는 무시되기 때문이다.
예를 들어, 20대 남성의 평균 신장이 173cm라고 할 때, 그들 중 상당수는 180cm보다 크고, 다른 몇몇은 165cm보다 작을 것이다. 평균은 이러한 차이를 드러내주지 않는다.
(2) 중앙값(median)
중앙값은 관측치를 오름/내림차순으로 나열했을 때 가장 가운데에 위치한 값을 의미한다. 즉, 중앙값에서 히스토그램은 그 면적이 양분된다.
① 숫자가 1, 5, 7과 같이 주어졌을 때의 중앙값은 5지만
② 숫자가 1, 2, 5, 7과 같이 주어졌을 때는 2와 5 사이의 어떤 값도 중앙값이 될 수 있다. 대부분 2와 5의 중간인 3.5를 중앙값으로 선택한다.
(3) 최빈치(mode)
최빈치는 가장 많이 관찰되는 값이다. 숫자가 1, 2, 2, 7, 8과 같이 주어졌을 때의 최빈치는 2이다.
히스토그램은 최빈치에서 그 높이가 제일 높다
(4) 평균과 중앙값의 관계
해당 자료의 평균은 55.3kg이다. 하지만 절반인 50%의 여성이 평균체중보다 무거울 것이며, 나머지 절반인 50%의 여성이 평균체중보다 가볍다는 말은 아니다. 즉, 평균과 중앙값이 같은 값이 된다는 보장이 없다.
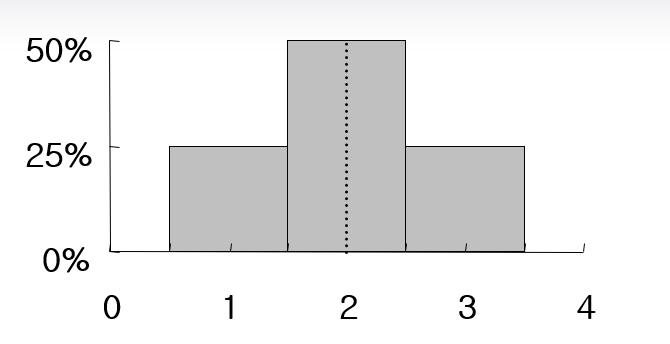
다음 그림과 같이 히스토그램이 특정값을 중심으로 대칭이면 평균과 중앙값은 같다.

이전의 자료에서 3이 더 커지게 된다면 히스토그램의 대칭성은 사라지게 되며 다음과 같이 히스토그램의 중앙값은 2로 동일하지만, 평균은 중앙값으로 부터 점점 멀어지게 된다. 즉, 평균의 좌우 면적은 다를 수 있다.
※ 아이와 함께 시소를 타는 부모님을 생각하면 이해가 될 것이다.
히스토그램은 평균에서 균형을 이룬다.
(5) 히스토그램의 꼬리 유형

히스토그램엔 대표적인 세 가지 꼬리 유형이 있다.
좌측의 히스토그램은 꼬리가 오른쪽으로 늘어져 있으며(right skewed), 평균은 중앙값보다 크게 된다. 반면, 우측의 히스토그램은 꼬리가 왼쪽으로 늘어져있으며(left skewed), 평균은 중앙값보다 작게 된다.
어느 기업에서 사장 한 명은 엄청난 연봉을 받지만, 대부분의 일반 근로자들은 낮은 보수를 받는다고 가정했을 때, 평균임금은 일반 근로자들의 낮은 보수를 반영하지 못한 채 높게 나타나지만 중앙값은 낮게 나타날 것이다. -> 좌측의 히스토그램(분포가 대부분 왼쪽에 쏠려있음)
즉, 평균은 극단값에 큰 영향을 받으며, 그에 따라, 평균의 대표성이 훼손된다.
※ 시험 성적에서 중앙값이 평균보다 더욱 신뢰할 수 있는 지표가 되는 이유이다.
3. 제곱근-평균-제곱 (RMS)
| 0 | 1 | -3 | 3 | -1 |
위의 숫자들이 주어졌을 때, 해당 숫자들은 얼마나 클까?
평균은 0이지만, 평균은 숫자들의 대표적 크기를 알려주진 못한다. 양의 값이 음의 값을 상쇄한다는 사실만 알려줄 뿐이다.
숫자들의 대표적 크기를 측정하는 가장 쉬운 방법은 부호를 제거하고 평균을 구하는 것이다. 그 방법이 바로 제곱근-평균-제곱(root-mean-square) 방식이고, 실제 연산은 역순으로 한다.
① 제곱(S): 모든 수를 제곱하여 부호를 없앤다.
② 평균(M): 제곱된 값들의 평균을 구한다.
③ 제곱근(R): 그 평균의 제곱근을 취한다.

즉, 다음과 같이 계산할 수 있다.
4. 표준편차
자료의 숫자들은 평균으로부터 어느 정도 떨어져 있다. 우선 개별 숫자를 평균으로부터의 편차로 표시해보자.
(평균으로부터의 편차) = (개별 숫자) - (숫자들의 평균)
표준편차(standard deviation)는 개별 숫자들이 평균으로부터 떨어져 있는 정도를 측정한다. 이때 표준편차는 편차들의 RMS와 대체로 비슷하다.
(1) 표준편차 계산법
[ 20, 10, 15, 15 ]
다음과 같은 숫자가 주어졌을 때 표준편차를 구하는 방법은
① 평균을 구한다. (20 + 10 + 15 + 15) / 4 = 15
② 평균으로부터의 편차를 구한다. 주어진 숫자에서 평균을 빼주면 된다. -> [5 ,-5 ,0, 0]
③ 편차들의 RMS 값을 구한다. ※ 하지만 평균을 구할 때 자료의 개수로 나누지 않고 '자료의 개수 -1'로 나눈다

위의 계산법을 통해 표준편차를 구할 수 있다. 해당 값을 일반화된 수식으로 나타낸다면

다음과 같이 나타낼 수 있다. 표본표준편차는 하나의 관측치가 표본평균으로부터 대략 얼마나 떨어져 있는지를 보여준다.
먼저 편차의 제곱을 더하고 이를 '자료의 개수 -1'로 나누어 표본 분산을 구한 뒤 그 제곱근을 취함으로써 표본표준편차가 얻어진다.
이때 '자료의 개수 -1'은 자유도(degrees of freedom) 개념으로, 밑에서 다루겠다.
(2) 68-95 법칙
위에서 언급한 국민건강영양조사에는 10대 이상의 여성 1960명이 표본으로 선정되었다. 이들의 평균 신장은 155.4cm이고, 표준편차는 6.8cm이다. 많은 수의 숫자는 평균으로부터 1표준편차 이내만큼 떨어져있다. 그리고 일부의 숫자만이 평균으로부터 2 또는 3 표준편차 이상 떨어져있게 된다.

숫자들의 약 68%가 평균에서 1SD(표준편차) 떨어진 영역 내에 존재하며 나머지 32%는 그 영역 밖에 존재한다.
그리고 대략 95%가 평균에서 2SD(표준편차) 떨어진 영역 내에 존재하며 나머지 5%는 그 영역 밖에 존재한다.
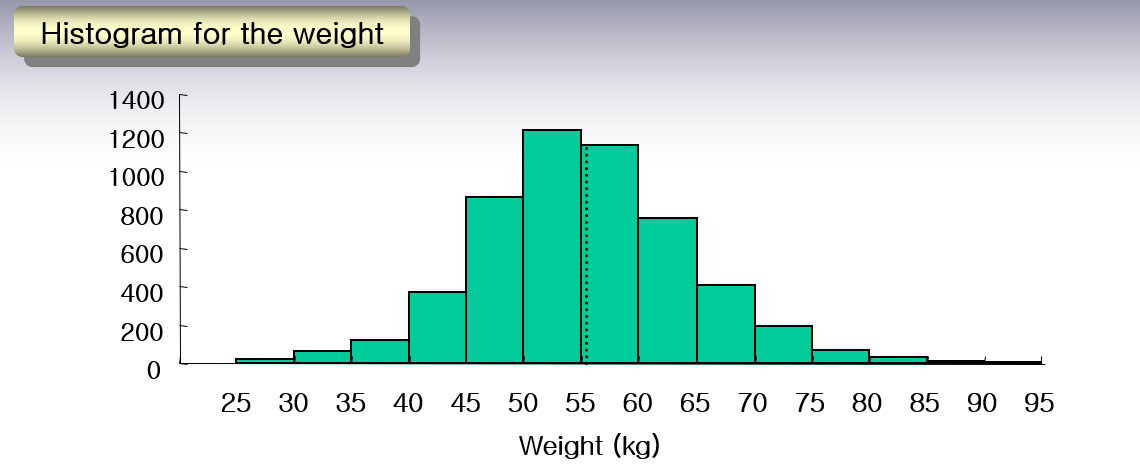
(3) 실제 활용

위의 그림은 2007년 국민건강영양조사자료이다. 평균은 점선으로 표시되어있고, 각각 1SD, 2SD 내의 영역은 음영으로 표시되어 있다.
하지만 실제 데이터를 봤을 때 좌측 그림의 음영 영역은 69.5%로 나타난다. 즉, 68-95의 법칙은 어느정도 잘 성립하지만, 그 숫자가 정확히 68%, 95% 등으로 나타나지는 않는다. 이는 '정규분포'에 관한 내용으로 다음 장에서 다루기로 하겠다.
5. 자유도
앞에서 표준편차를 구할 때 제곱한 편차들을 합친 뒤 무언가 하나의 숫자로 나누어 주었다. 일종의 '평균'을 구한 셈인데, 그 무언가의 숫자가 바로 자유도이다. 자유도는 합쳐진 값들 중에서 실질적으로 '자유로운' 값들의 개수와 같다.
평균으로부터의 편차는 자료의 개수만큼 존재한다. 하지만 편차의 합은 언제나 0이다.
[ 20, 10, 15, 15 ]
해당 숫자들의 평균은 15이고, 편차는 [5, -5, 0, 0]으로 나타난다. 이때 편차의 합은 0이다. 만일 3개의 편차값을 안다면 나머지 1개의 편차값이 주어지지 않더라도 우리는 네번째 편차의 값을 알 수 있다. 즉, 해당 자료에선 3개의 값만이 자유롭기에 자유도는 3으로 나타난다.
그렇다면 왜 표준편차를 구할 때 자료의 개수가 아닌 자유도로 나눌까? 이는 자료의 개수로 나눴을 때, 표본으로부터 구한 표준편차는 실제의 표준편차를 '과소평가'하게 되기 때문이다. 극단적으로, 자료가 '5' 하나밖에 없다면, 평균은 5가 되고, 편차의 값은 0이 된다.
표준편차는 편차의 RMS 값을 구하는 것이었다. 자료의 개수,자유도로 모두 나눠보자. 편차는 0이다.
① 자료의 개수(1)로 나눌 때 RMS = 0/1의 제곱근 -> 0
② 자유도(0)로 나눌 때 RMS = 0/0의 제곱근 -> 부정형(indefinite form)으로, 수학적으로 정의되지 않는다.
표준편차의 정의를 다시 생각해보자. 표준편차는 '평균으로부터 퍼진 정도'이다. 하지만 자료의 개수가 하나라면 그 퍼진 정도는 0이 아니라, 구할 수 없다. 즉, 표본표준편차를 구할 땐 자유도로 나눠야 한다.
6. 측정오차, 편의, 이탈값
(1) 측정오차
동일한 대상을 여러 번 측정할 때 매번 동일한 측정치가 얻어지진 않는다. 개별관측치를 실제의 값과 다르게 만드는 측정 상의 오차를 측정오차(measurement error)라고 한다. 측정오차로 인해 관측치의 값은 측정할 때마다 변한다. 그럼에도 측정을 반복하는 이유가 있는데,
첫째, 단 한 번 측정한 값은 측정오차 때문에 참값과 다르다. 이때 여러 번 측정하여 관측치들의 평균을 내면 오차가 줄어든다.
둘째, 여러 번 측정한 값을 상호 비교하면 측정오차의 크기를 짐작해볼 수 있다.
관측치가 어느 정도로 다르게 나올 것인지를 알기 위해선 관측을 여러 차례 반복하면 된다. 측정오차의 크기는 관측치들의 표준편차를 통해 알아낼 수 있다.
(개별 관측치) = (실제의 값) + (측정 오차)
실제값은 상수로 고정되어 있기 때문에, 측정오차의 표준편차는 개별 관측치의 표준편차와 같다.
즉, 관측치들의 표준편차를 구하는 과정을 통해 측정 오차를 구할 수 있게 된다.
(2) 편의
측정오차 이외에도 관측치를 실제의 값과 다르게 하는 요인이 존재한다. 가령 정육점 주인이 쇠고기의 무게를 잴 때 손가락으로 고기를 누른다던가, 재단사가 95cm 길이의 줄자에 1m라고 표시한다면 고기의 무게와 옷감의 길이는 실제와 다를 것이다. 이러한 체계적인 오차는 측정을 반복한다고 하더라도 상쇄되지 않는다.
이처럼 방향성을 갖는 체계적인 오차를 편의(bias)라고 부른다. 편의는 모든 관측치에 동일한 방향으로 영향을 주지만, 측정오차는 관측치를 참값보다 크게 할 수도 있고 작게 할 수도 있다.
만약 관측치들이 편의에 의해서도 영향을 받는다면 앞서 소개한 수식은 아래와 같이 바뀐다.
(개별 관측치) = (실제의 값) + (편의) + (측정오차)
편의가 존재하지 않는다면 반복측정으로 얻어진 값들의 평균은 실제값에 가까워진다. 즉, 측정오차는 상쇄되어 줄어들고 궁극적으론 없어지게 된다. 하지만 편의가 존재하는 경우 여러 관측치에 걸쳐 평균을 구하더라도 그 평균은 실제값과 다르게 나타난다.
대개 편의는 측정과정 자체만을 보고 찾아내기 어렵기에 관측치를 외부의 기준이나 이론적인 예측치와 비교하여 편의의 존재 여부를 늘 검토해야 한다.
(3) 이탈값
이탈값(outlier)은 극단적인 관측치를 의미한다. 아무리 주의를 기울인 실험에서도 소수의 이탈값은 나타날 수 있다. 많은 경우, 이탈값이 나타났을 때 이를 무시하는 방식을 선택한다. 나름대로의 이론에 맞지 않는다고 판단하기 때문이다.
하지만 어떤 관측의 결과를 있는 그대로 받아들이지 않고 관측치가 어떻게 나타날 것이라고 기대하면서 관측 과정에 주관적으로 개입해서는 안 된다. 자의적인 기준을 정해두고 마음에 들지 않는 자료를 버린다면 분석결과는 심각하게 왜곡된다.
의미 있는 분석결과를 얻기 위해서는 가급적 모든 자료를 받아들여야 한다. 특정 실험/표본추출 등을 추가적으로 반복했을 때에도, 해당 값이 다시는 나타나지 않을 '명백한 착오'여야만 이탈값을 무시할 수 있게 된다.
* 해당 글은 류근관 저서의 <통계학> 제 3판의 내용을 바탕으로 합니다 *
'통계학' 카테고리의 다른 글
| [통계학] 6장 - 회귀분석 (5) | 2024.12.04 |
|---|---|
| [통계학] 5장 - 상관관계 (5) | 2024.11.28 |
| [통계학] 4장 - 정규분포로의 근사 (2) | 2024.11.24 |
| [통계학] 2장 - 히스토그램 (9) | 2024.11.20 |



