1. 기울기와 절편
(1) 기울기
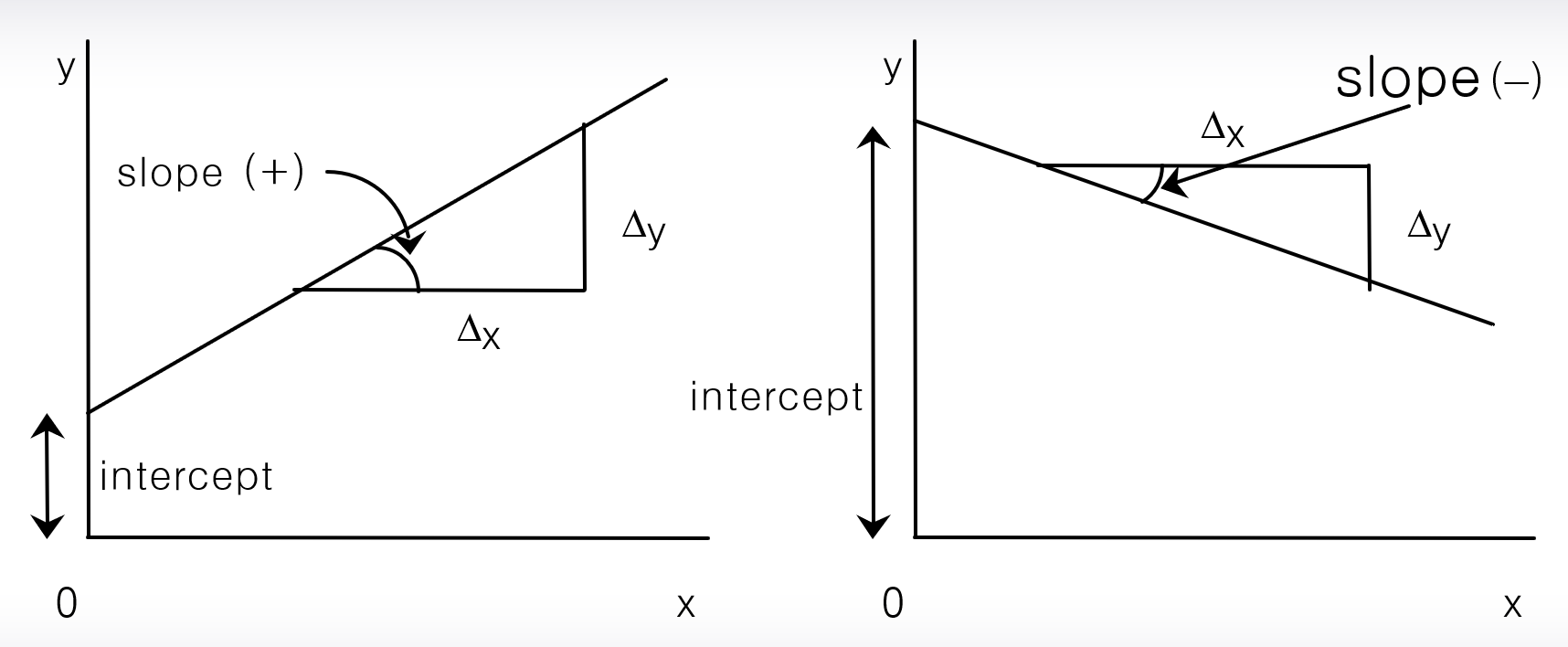
하나의 직선은 기울기와 절편으로 표현된다. 절편은 x가 0일 때 y값을 의미하고 기울기는 x가 1단위 증가할 때 y가 증가하는 정도를 의미한다.

해당 그림은 만 30-40세의 도시 남성 198명을 대상으로 조사한 교육과 월소득의 관계이다. 교육년수의 평균은 12.5년, 표준편차(SDx)는 2년이다. 소득은 평균이 163만원, 표준편차(SDy)는 77만원이다. 교육년수와 소득간의 상관계수(r)는 0.33이다. 이때 회귀직선은 교육수준별로 평균소득의 추정치를 하나의 직선으로 근사시킨다. 직선은 우상향하기에 교육을 많이 받을수록 소득이 높아지는 경향이 있다.
교육이 1SDx만큼 증가할 때 소득은 r * SDy만큼 증가한다. 즉, 교육을 1SDx = 2년 더 받으면 소득은 0.33 * SDy = 25만 4천원만큼 증가하는 것이다. 따라서 교육을 1년 더 받으면 소득은 12만 7천원만큼 증가한다. 즉, 이 회귀직선의 기울기는 12.7이고, 그 단위는 '만원/년' 이다.
(2) 절편
회귀직선의 절편은 x = 0일 때의 y축 높이이다. 이는 교육을 전혀 받지 않은 남성들의 평균소득에 해당한다. 이런 남성은 평균보다 12.5년만큼의 교육을 덜 받았다. 기울기의 값으로부터 1년의 교육은 소득으로 12만 7천원의 가치가 있음을 보았다. 따라서 교육을 전혀 받지 않은 남성의 소득은 평균소득보다 12.5년 * 12만 7천원 = 158만 7,500원만큼 낮다. 따라서 무학력 남성의 소득은 163만원 - 158만 7,500원 = 4만 2,500원으로 추정된다. 이것이 절편이다.
| 회귀직선의 기울기는 x가 1단위 증가할 때 y가 증가하는 정도를 나타낸다. 회귀직선상에서는 x가 1SDx만큼 증가할 때 y가 r * SDy만큼 증가한다. 따라서, 기울기 = r * (SDy/SDx) |
회귀직선에 대응하는 방정식을 회귀방정식(regression equation)이라고 부른다. 위의 회귀방정식은 다음과 같이 나타난다.
● (소득의 추정치) = 4만 2,500원 + (1년당 12만 7,000원) * 교육년수
예시문제) 도시 여성 근로자 108명에 대한 교육과 월소득의 자료가 다음과 같다고 하자.
| 교육 평균(x) = 11년 | 표준편차(SDx) = 3.6년 |
| 소득 평균(y) = 89만원 | 표준편차(SDy) = 60만원 |
| 상관계수 = 0.43 |
(1) 교육년수로부터 소득을 추정하는 회귀직선을 구하라.
(2) 교육년수가 12년, 16년인 여성의 소득을 회귀방정식을 통해 추정하라.
(1) 기울기 = r * (SDy/SDx) = 0.43 * (60만원/3.6년) = 7만 2천원이고, 이는 1년의 교육에 7만 2천원의 가치가 있다는 것이다. 절편은 x가 0인 지점의 y값이므로 소득 평균 89만원 - (11 * 7만 2천원) = 9만 8천원으로 나타나게 된다. 이에 따라 회귀방정식은
-> (소득의 추정치) = 9만 8천원 + (1년당 7만 2천원) * (교육년수)
(2) 12년 교육 받은 도시 여성 근로자의 추정 소득은 절편인 9만 8천원 + (12년 * 7만 2천원)을 통해 96만 2천원, 16년 교육 받은 도시 여성 근로자의 추정 소득은 9만 8천원 + (16년 * 7만 2천원)으로 125만원이다.
-> 96만 2천원, 125만원
(3) 외부개입 - 내부반응
기울기는 누군가 외부로부터 '개입하여' x값을 변화시킬 경우, 이에 반응하여 y값이 얼마나 변화하는가를 알기 위해 사용한다. 기울기에 대한 이러한 '외부개입-내부반응'식의 해석은 자료가 '통제된 실험'에 의해 도출되었을 경우에 일반적으로 타당하다. 혼동요인이 존재할 수 있기 때문에 관측자료에서 구한 회귀방정식의 기울기를 '외부개입-내부반응'의 척도로 해석하려면 세심한 주의가 요구된다.
위의 도시 여성 근로자를 예시로 설명하자면, 대학을 마친 여성은 고등학교만 졸업한 여성보다 평균적으로 28만 8천원을 더 버는 것으로 고나측되었다. 그렇다면 정부가 강제로 고등학교 학력을 가진 여성 가운데 일부를 무작위로 뽑아 강제로 대학에 보내 4년간 교육을 받게 시키는 경우에도 이들의 소득이 고졸자에 비해 28만 8천원만큼 증가할 것인가? (이러한 해석이 바로 외부개입-내부반응 식의 해석이다.)
보기에서 사용한 자료는 통제된 실험 또는 외부개입을 통해 얻어낸 것이 아니라 표본조사를 통해 얻어낸 관측자료일 뿐이다. 이 조사에서 여성들은 스스로 교육 수준을 선택하였다. 따라서 관측된 두 집단은 지적 능력, 야망, 가정환경 등 다른 많은 요인에서도 차이를 보일 것이다. 실험자료가 아니어서 다른 요인들이 잘 통제되지 않았기 때문이다. 따라서 두 집단 사이에서 관측된 소득의 차이를 순전히 교육의 차이로만 설명하기는 어렵다.
즉, 교육이 소득에 미치는 효과를 왜곡시킬 수 있다.
| 회귀방정식은 교육과 소득의 관계를 추정하는 좋은 방법이다. 하지만 기울기를 교육수준의 변화가 소득에 미치는 순수효과, 즉 외부개입-내부반응의 효과로 이해하면 곤란하다. 교육의 효과뿐만 아니라 다른 변수들의 효과도 기울기에 반영되어 있기 때문이다. |
(4) 다중회귀분석
실험이 불가능한 경우 다중회귀분석(multiple regression) 방법을 사용한다. 이는 다른 요인을 통제하기 위한 하나의 통계적 방법이다. 원칙적으로 실험을 통한 통제가 가장 좋은 통제방법이다. 하지만 실험이 불가능하다면 통계적 통제(statistical control)라도 하는 편이 낫다. 다중회귀분석은 통계적 통제의 수단으로 종종 사용된다.
2. 최소자승법
두 변수간의 관계를 시각적으로 보기 위해 산포도를 이용한다. 이때 산포도상의 점들을 가장 잘 반영하는 직선은 '보다 많은 점들에 보다 가까이' 다가가도록 직선을 그려야 한다.
● 첫째, 각각의 점으로부터 한 직선까지의 거리를 정의한다.
● 둘째, 전반적인 거리가 가능한 한 작아질 때까지 직선을 이동시켜 '최적의 직선'을 찾아낸다.
● 이 최적의 직선이 바로 회귀직선이고, 직선에 대응하는 절편과 기울기가 바로 회귀직선을 규정하는 최소자승추정량이 된다.
첫 단계에서 점으로부터 직선까지의 거리를 정의할 땐, 점으로부터 회귀직선까지의 수직거리들의 평균인 RMSE를 사용한다.
| 모든 직선 중에서 x를 통해 y를 추정할 때 발생하는 추정오차들의 전반적인 크기를 가장 작게 만들어주는 직선이 바로 y의 x에 대한 회귀직선이다. |
회귀직선은 종종 최소자승직선이라고 불린다. 이는 최소화의 대상인 RMSE를 구할 때 우선 오차들을 제곱, 즉 자승(自乘)하여 자승오차(squared error)를 구하기 때문에 붙여진 이름이다. 회귀직선은 자승의 산물인 RMSE(root mean squared error)를 최소로 만드는 직선인 것이다.
| 추의 무게(kg) | 길이(cm) |
| 0 | 439.00 |
| 2 | 439.12 |
| 4 | 439.21 |
| 6 | 439.31 |
| 8 | 439.40 |
| 10 | 439.50 |
후크(Robert Hook)는 물체를 매달았을 때 용수철의 늘어난 길이를 관측했다. 물체와 길이 사이의 관계는 선형으로 즉, 물체를 매단 뒤 잰 용수철의 길이는 y = a + bx + (오차)로 표현된다.
x와 y는 변수이고 a와 b는 용수철의 종류에 따라 결정되는 상수들이다. 위의 자료에서 매단 무게와 용수철의 늘어난 길이간 상관계수는 0.99로 1과 거의 같다. 거의 직선이지만, 아마도 측정오차로 인해 선형관계에서 약간 차이가 발생한 것이다. 이로 인해 점들은 정확하게 한 직선상에 위치하지 않는다.

이럴 때 RMSE를 최소화하는 최적의 직선인 회귀직선을 구하는 것이다. RMSE를 최소화하도록 a와 b를 정하며, 이렇게 추정한 값을 최소자승 추정량(least squares estimator)이라고 부른다.
a = 439.01, b = 0.05로 나타났으며, 이는 추의 무게가 1kg 늘어날 때마다 용수철은 439.01cm로부터 0.05cm씩 늘어난다는 것이다. 하지만 위의 표와 비교하면 값이 다른데, 이 경우엔 관측치보다 추정치를 더 신뢰한다. 단 한 번의 관측치보다 모든 여섯 개의 관측치를 함께 고려한 결과가 더 정확할 것이기 때문이다.
3. 회귀분석은 만병통치약이 아니다
회귀직선은 어떤 산포도에도 그려 넣을 수 있다. 다만 다음 두 가지 사항을 고려해야 한다.
● 첫째, 변수간의 관계가 비선형성을 띠면 어떻게 할 것인가?
● 둘째, 변수간의 관계가 선형성을 보인다고 해서 회귀직선이 반드시 의미가 있는가?
예를 들어 한 여학생이 있다. 그녀는 직사각형의 넓이를 구하는 공식을 모른다. 다만 넓이는 둘레와 관련되어 잇을 거라고 추측한다. 다음으로 모양과 크기가 다른 20개 직사각형에 대해 각각 넓이와 둘레 길이를 잰다. 넓이를 둘레 길이에 회귀분석한 결과 다음과 같은 방정식을 얻는다.
(넓이의 추정치) = -66cm^2 + (4cm * 둘레 길이)
넓이와 둘레 길이간의 상관계수는 0.98로 나타났고, 그녀는 해당 방정식이 강한 설득력을 갖는다고 믿게 되었다.

산포도는 다음과 같이 나타났으며, 하나의 점은 하나의 직사각형을 나타낸다. 회귀직선 또한 그려져 있다. 하지만, 하나의 직사각형에서 밑변의 길이와 높이는 넓이와 둘레 길이에 모두 영향을 준다.
(넓이) = (밑변의 길이) * (높이),
(둘레 길이) = 2 * (밑변의 길이 + 높이)
위의 식과 같은 관계가 이미 존재하지만, 회귀분석으로 그 관계를 파악하려는 시도는 어리석은 일이다. 그녀가 회귀분석을 아무리 많이 하더라도 둘레길이와 넓이간의 관계는 영원히 밝혀내기 어려울 것이다.많은 사람들이 그녀와 같은 실수를 범하기에 회귀분석이 정말로 의미가 있는지 고려해야한다.
4. 다중회귀분석
종종 제3의 변수가 두 변수에 영향을 미쳐, 관심의 대상인 두 변수 상호간의 순수한 관계를 왜곡시키게 된다. 이럴 경우 제3의 변수를 통계적으로 통제할 필요가 있다.
● 자료를 제3의 변수값에 따라 분류하여 집단별로 따로따로 분석하기
● 다중회귀분석 이용하기
예를 들어 아파트의 평수와 연령이 가격에 어떠한 영향을 주는지 살펴보기 위해 다음 회귀식을 추정한다고 하자.
(아파트 가격) = a + b1(평수) + b2(연령) + 오차
연구자는 이 식을 통해 평수가 아파트 가격에 미치는 순수효과인 b1과, 연령이 아파트 가격에 미치는 순수효과인 b2를 알고싶어 한다. 2000년, 강남지역의 아파트 자료를 모아 회귀분석을 한 결과 다음을 얻었다.
(아파트 가격의 추정치) = -20.394 + 1,549 * (평수) + 0.76 * (연령) (단위: 만원)
위의 식은 평수가 1평 늘어날 때마다 아파트 가격이 평균적으로 1,549만원 비싸지며, 연령(건축연도)이 1년 앞설 때마다 아파트 가격이 7,600원 더 비싸진다고 해석할 수 있다. 그런데, 상식적으론 아파트의 연령이 많아질수록 가격이 싸질 것으로 추측할 수 있다. 이러한 결과가 나온 것은 제 3의 혼동요인이 존재하기 때문이다.
단지규모가 제 3의 혼동요인으로 나타났다. 1970년대 강남 아파트 개발이 시작된 이래 최근으로 올수록 대규모 단지가 소진되며, 아파트가 위치한 단지규모가 작아져 왔다. 즉, 아파트 나이와 단지규모간 체계적인 관계가 존재한다. 또한, 단지 규모가 크면 편의시설이 발달하여 일반적으로 아파트 가격이 높다.
-> 아파트 연령이 높을수록 단지규모는 크며, 그에 따라 다양한 편의시설도 발달해있기에 아파트 가격이 비싸다.
위의 다중회귀식에 단지규모 변수를 추가해보자.
(아파트 가격의 추정치) = -20.291 + 1,538 * (평수) -137 * (연령) + 2 * (단지규모)
제 3의 요인인 단지규모를 변수에 추가해 통제한 결과, 아파트 연령과 아파트 가격간의 관계가 보다 상식에 부합되게 얻어졌다. 이처럼 변수를 추가하며 제 3의 혼동요인을 통제할 수 있고, 단지규모와 같은 양적인 변수 이외에도 질적인 변수도 통제할 수 있다.
더미변수는 질적인 변수를 분석에 용이하도록 0과 1의 수치로 표현한 변수이다. 예컨대 남성이면 1, 여성이면 0의 값을 부여하거나, 노동조합원이면 1, 그렇지 않으면 0의 값을 부여하는 것이다.
5. 총변동의 분해
(1) yi - ȳ의 분해

해당 표는 1976-2000년도에 대해 연도별 연간 통화증가율과 인플레이션율을 나타낸다. 해당 구간의 평균 통화증가율은 22.03%, 평균 인플레이션율은 10.56%로 나타났는데, 1991년의 통화증가율과 인플레이션율은 평균보다 높게 나타난 것을 알 수 있다. 어디서 이러한 차이가 발생했을까?

많은 경제학자들은 통화증가율이 인플레이션율을 잘 설명한다고 본다. 이러한 견해를 받아들여 인플레이션율을 통화증가율에 대해 회귀분석하였다. 추정된 회귀직선의 식을 ŷ = a + bx라고 하자. 우선 기호들을 정리할 필요가 있다.
● a와 b는 각각 추정된 절편과 기울기로 각각 -1.87, 0.46의 값을 갖는다.
● 앞서 예로 든 1991년의 인플레이션율과 통화증가율을 각각 yi와 xi로 표시하자.
● 평균으로 측정한 지난 23년간의 전형적인 인플레이션율을 ȳ라고 하자. 1991년도의 인플레이션율은 평균보다 yi - ȳ만큼 높았다.
수치상으로 이 차이는 1.24%p 였다. 둘의 차이를 다음 식과 같이 분해해보자.
yi - ȳ = [(a + bxi) - ȳ] + [yi - (a + bxi)]
T = R + E
이 식에서
T는 1991년도 인플레이션율이 평년과 다른 부분 전체를
R은 1991년도에 해당하는 회귀직선상의 높이가 평균 인플레이션율 ȳ를 지나는 수평선으로부터의 차이를
E는 1991년의 인플레이션유링 회귀직선으로부터 차이나는 순수한 오차를 나타낸다.

즉, 다음과 같이 나타난다. 다시 요약하자면
(R) = 회귀직선의 y값과 평균 y값의 차이
(E) = 주어진 점의 인플레이션율과 회귀직선의 수직상 거리 (실제 관측값과 회귀 예측값의 차이)
(T) = 인플레이션율이 평균과 다른 전체 부분
통화증가율이 인플레이션율에 중요한 영향을 미치는 것은 사실이지만, 다른 많은 요인들도 인플레이션에 영향을 미친다. 심리적 요인, 원자재 가격, 환율 등이 그 예시다. 1991년도의 인플레이션율은 평년 수준을 1.24%p 웃돌았는데, 이 차이를 분해해서 살펴보면 다음과 같이 나눌 수 있다.
① 1991년도의 통화증가율이 평년수준보다 높았기 떄문에 초래된 부분 (R)
② 통화증가율 이외의 기타요인에 의해 초래된 부분 (E)
즉, R(0.12%)은 전체 1.24%의 차이 가운데 회귀직선, 즉 통화증가율에 의해 설명될 수 있는 부분이고, E(1.12%)는 기타요인에 의한 부분으로 통화증가율로는 설명이 안 되는 나머지 부분이다. 그렇기에 T에서 차지하는 R의 비중이 E의 비중보다 상대적으로 크면 우리는 x로 나타낸 통화증가율이 y로 표현한 인플레이션율을 잘 설명한다고 말한다.
(2) SST, SSR, SSE
그러나 점 하나하나에 대해 이렇게 요약하다보면 식의 수가 많아져 난감해지기에, 여러 관측치에 대한 값을 하나의 종합적인 언급으로 요약할 필요가 있다.
yi - ȳ = [(a + bxi) - ȳ] + [yi - (a + bxi)]
T = R + E
해당식의 모든 항들을 각각 제곱해서 합쳐보면 각각의 점들에 대한 수직 거리를 모두 고려한 지표가 될 것이다.

다음과 같이 요약할 수 있게 된다. 즉, 윗식은 y의 총변동을 회귀직선에 의해 설명되는 변동분과 회귀직선에 의해 설명되지 않는 변동분으로 분해한다.

총변동 가운데 설명되는 변동분이 차지하는 비중이 클수록 회귀직선의 설명력은 그만큼 더 높다. 회귀직선의 설명력을 나타내주는 지표를 결정계수(coefficient of determination)라고 부르고 R²으로 표기한다.
| 종속변수의 총변동(SST)은 설명변수에 의해 설명되는 변동분(SSR)과 설명되지않는 변동분(SSE)의 합으로 분해된다. 총변동에서 차지하는 설명되는 변동분의 비율을 결정계수라고 한다. |
결정계수는 회귀직선의 설명력이 최대일 때 1이 되고, 최소일 때 0이 된다. 해당 값은 0과 1 사이에 존재하며, 단순회귀분석의 경우 결정계수 R² 값은 상관계수 r의 제곱과 같게 된다.
설명변수가 추가될 때마다 결정계수는 늘어난다. 설명변수에 의해 설명되는 변동분의 비율이 바로 결정계수이기 때문이다. 즉, 다중회귀분석에서 변수를 추가하면 추가할수록 결정계수는 무조건 커진다. 이러한 문제를 해결하기 위해 이른바 '조정된 R²' (adjusted R²)을 다음과 같이 정의한다.
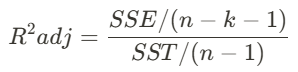
이때 n은 표본크기, k는 설명변수의 개수를 의미한다. SSE와 SST가 각각 그에 해당되는 자유도로 나누어진 형태를 취하고 있다. SST의 자유도는 표준편차를 구할 때처럼 n-1이 되고, 회귀분석의 잔차합인 SSE의 자유도는 표본크기로부터 추정된 모수의 개수를 빼주어야 한다.
설명변수가 k개 있다면 n으로부터 (k-1), 기울기, 절편만큼을 빼야 자유도가 되는 것이다.
n - {(k - 1) + 2} -> n - k - 1이 되는 것이며, 이때 + 2는 기울기, 절편을 의미한다.
조정된 R² 값은 설명변수가 추가된다고 해서 일방적으로 늘기만 하진 않는다. 이는 설명변수가 추가될수록 SSE의 값이 줄어들지만, 자유도도 덩달아 줄어들기 때문이다. 보통 단순 R² 기준으로 모형을 선정하는 것보다 조정된 R²을 사용하는 것이 더 합리적이다.
* 해당 글은 류근관 저서의 <통계학> 제 3판의 내용을 바탕으로 합니다 *
'통계학' 카테고리의 다른 글
| [통계학] 10장 - 이항공식 (2) | 2025.03.15 |
|---|---|
| [통계학] 9장 - 확률이란 무엇인가 (4) | 2025.02.04 |
| [통계학] 데이터 사이언스 인터뷰를 위해 필수적으로 알아둬야 할 통계적 개념 (9) | 2024.12.11 |
| [통계학] 7장 - 회귀분석의 오차 (4) | 2024.12.07 |



